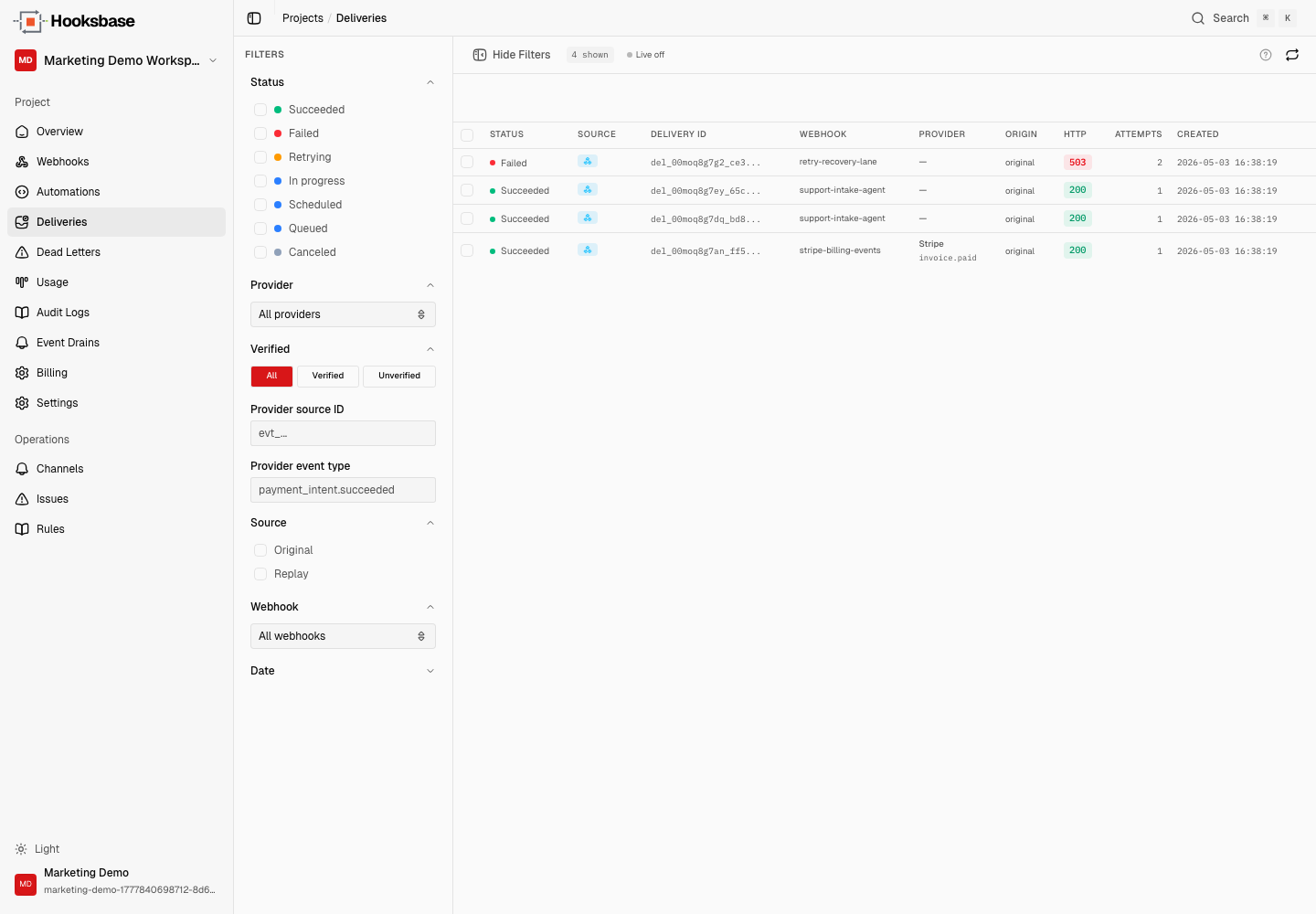
You know the arc: the agent works on your laptop, ships to staging, gets a blessing from the team, goes live. Two weeks later there's an incident that has nothing to do with the agent and everything to do with the event layer underneath.
This is the checklist we'd walk through before putting an agent in front of real traffic. It's not exhaustive, but it's the stuff that keeps us from paging on things the framework should have covered.
1. Quotas actually gate your agent
Your monthly LLM budget is finite. Your agent's token spend is proportional to how many events reach it. So the event layer has to enforce a hard ceiling, not an aspirational one.
Hooksbase enforces quotas at two layers:
- Exact accounting for stored payload bytes, backlog depth, monthly deliveries, and file storage. Atomic conditional writes, not read-then-check-then-write races.
- Refill-based rate limiting for ingest rate and 24h replay volume. No bursty drain-and-wait surprises.
Both fail closed if reconciliation is in a bad state — you get a 503 instead of silently accepting traffic you can't bill.
2. Ordering matches the agent's tolerance
Does your agent care about order? Be explicit.
parallel(default) — multiple events can be in flight at once. Fast, but if event B arrives before event A completes, the agent sees B first.strict_fifo(Pro+) — the head delivery blocks subsequent ones until it succeeds or terminally fails. Slow, but ordered.
Most agents don't need strict FIFO. The ones that do really need it — think "process these customer state changes in sequence or the account balance desyncs."
3. Throttling matches the agent's throughput
If your agent can only process 10 events per minute (because LLM rate limits, because one call takes 6 seconds, whatever), tell the event layer so.
Pro+ per-webhook throttling caps dispatch rate regardless of ingest rate. Hooksbase absorbs the burst in the backlog and drip-feeds the agent at the configured rate. The backlog is visible in the dashboard, so you know when to scale the agent or cut ingest.
4. DLQ is wired and watched
Terminal failures (after all retries) land in the DLQ. That's correct — but a DLQ nobody looks at is a silent failure.
- Set up a DLQ-accumulation alert (Pro+) so on-call gets paged when the DLQ exceeds a threshold
- Add a Pro+ event drain to your observability stack so DLQ entries show up in Axiom/Datadog with the rest of your agent telemetry
- Know your bulk DLQ re-drive workflow (Starter+) so fixing a bad prompt doesn't mean replaying 500 events by hand
5. Alerts on the real failure modes
Pro+ alerts are bundled into fixed families you configure thresholds for:
- Terminal failure spikes (agent-returned 5xx rate)
- Destination health (agent endpoint down)
- Backlog growth (agent slower than ingest)
- Secret lifecycle (signing key about to expire, rotation overdue)
- Quota breaches (monthly deliveries approaching limit)
- SLO breaches (per-webhook SLO drift)
- DLQ accumulation
- Paused drains
- Degraded drains
- Quota thresholds
Turn on at least DLQ, backlog, and destination health before going live. The others are nice-to-have until they aren't.
6. Audit logs for regulated flows
Business+ projects get an audit log API covering webhook lifecycle, secret rotation, API-key actions, replay requests, DLQ re-drive, and bulk operations. Audit payloads exclude plaintext secrets — the record is who-did-what-when, not the secret itself.
If your agent handles regulated data (financial, health, PII), security review will ask for this. Having it wired up before the review is less painful than bolting it on during.
7. You can recover without support
Before you go live, rehearse a recovery:
- Pick a delivery in the dashboard
- Click replay
- Confirm the agent re-ran with the same input bytes
- Do the same for a DLQ'd entry with DLQ re-drive
- Trigger a Starter+ bulk replay on a filtered selection
If your team hasn't done this, they'll do it for the first time during an outage. That's the worst possible moment to learn the UI.
8. Observability outside Hooksbase
One event drain on Pro ("1 drain") is enough to pipe delivery lifecycle events into Axiom, Datadog, object storage, or OTLP HTTP. Do it. Your agent team already has a place they look during incidents; agent event failures should show up there.
Business+ gets 3 drains, Enterprise gets unlimited.
9. Your signing rotation plan
Outbound deliveries are signed with HMAC (Standard Webhooks-compatible headers). Secret rotation has a configurable overlap window where both old and new secrets sign each delivery simultaneously, so the consumer can migrate without downtime.
- Know how to trigger a rotation
- Know the overlap window and when the old secret expires
- Have a runbook for "the consumer hasn't migrated yet"
10. Your downgrade behavior
If billing fails and the project gets downgraded, premium config stays visible but is runtime-blocked. Scheduled webhooks below Starter skip firing. Queued bulk jobs fail with entitlement errors.
Nothing is silently lost, but you should know what degraded mode looks like before you hit it — not after.
None of this is specific to Hooksbase. Any event layer under an agent needs these properties. The checklist is the checklist.
If it's useful, treat this as the minimum bar. Agents fail in ways classical APIs don't. The event layer is the one part of the stack you can make boring.