Every team building an AI agent right now follows the same arc. Week one: an afternoon prototype. Week two: a Slack demo that feels like magic. Week four: it's in front of the first customer. Week six: someone asks what happens when an event gets dropped.
That's when the event-infrastructure problem shows up. And it doesn't go away.
The problem isn't the agent
The agent itself is solvable. Pick your framework, write your prompts, wire up your tools. The demo works.
The hard part is everything around it:
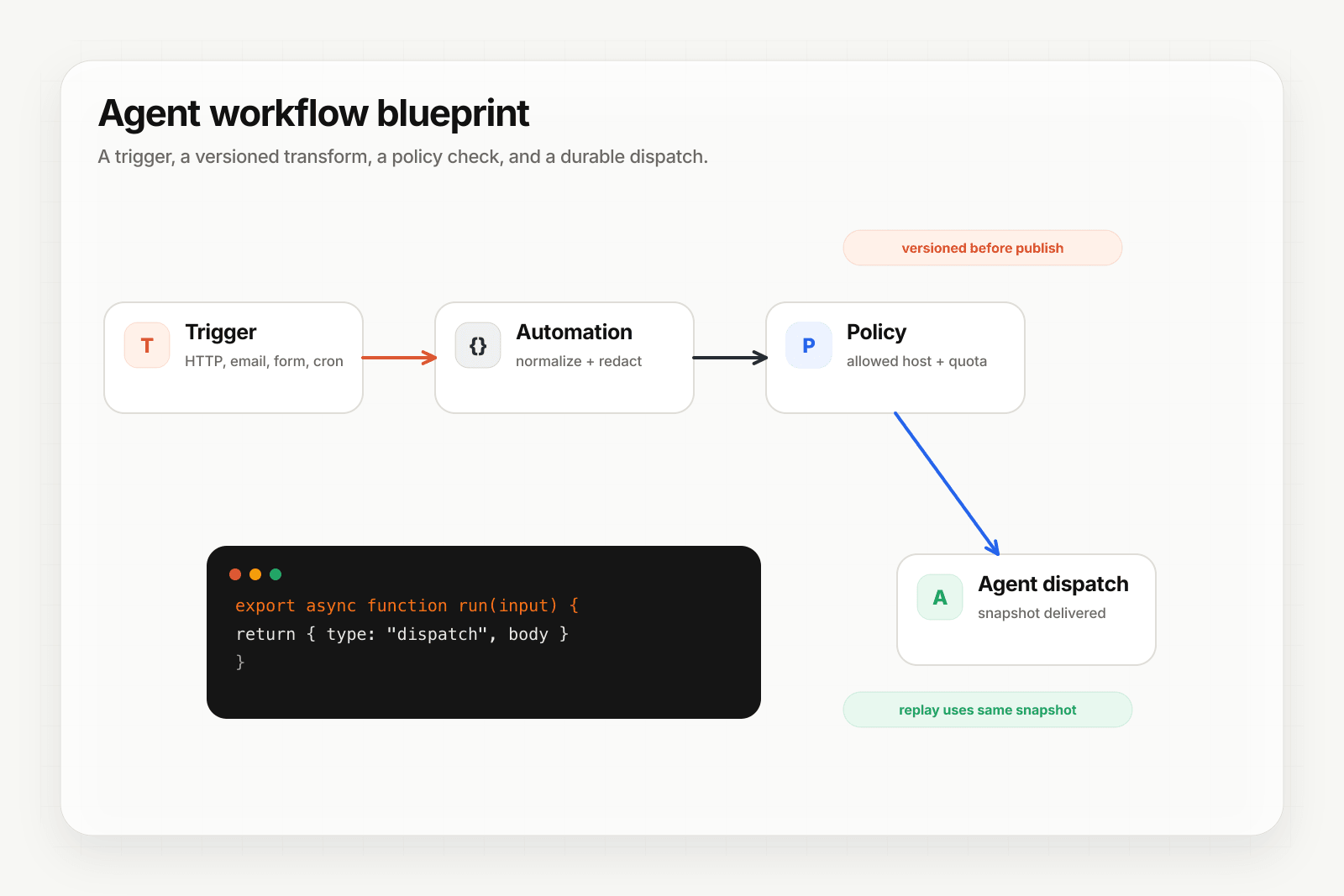
- How does the agent get triggered? HTTP? Fine. Email? Now you need an MX record, a parser, and a rate limiter. Form submissions? CORS, file uploads, idempotency. Cron? Pick a scheduler, host it, monitor it. Each channel is its own pipeline.
- What happens when the agent times out? Retries? Exponential backoff? How many attempts before you give up? Where do the failed events go?
- How do you know when events are dropping? Logs? Metrics? What's the shape of "an agent dropped 3% of events last week"?
- When a customer asks "why didn't my event trigger the agent?" — can you even answer? Do you have the payload? Attempts? The dispatch timestamp?
- When you change the agent's prompt or the transform that feeds it, can you replay last week's failures and get deterministic results?
Build all of that yourself and you've spent a quarter on infrastructure that isn't the agent. And you'll keep spending on it, because every new provider, every new channel, every new edge case needs the same plumbing.
What event infrastructure actually is
Event infrastructure for agents is the layer between "the world" and "your agent." It answers:
- How events reach the agent. Ingest from any channel — HTTP, email, forms, schedules — funneled into one delivery model the agent can consume.
- How events are routed. When you have multiple agents or destinations, priority-ordered rules decide where each event goes based on its content and source.
- How events are transformed. Adapt the source shape to what the agent expects without writing middleware.
- How delivery is guaranteed. Retries with backoff, strict ordering if you need it, throttling if the agent is slow, idempotency when the producer sends duplicates.
- How failure is recovered. DLQ for terminal failures, replay for deterministic re-run, bulk operations when a misconfiguration causes a wave of failures.
- How you observe the flow. Delivery history, attempt detail, metrics, alerts, and drains to the tools your on-call already watches.
This is not new technology. It's what mature SaaS products have been running internally for a decade. The difference now: agents need it immediately, because agents fail differently than APIs.
Why agents need it more than classical SaaS
A classical webhook consumer is deterministic. Same payload in, same response out. Retries are safe if the endpoint is idempotent.
Agents are non-deterministic. The LLM returns different text. Tool calls have real-world side effects. Retries cost tokens. Some failures are transient (rate limit) and replay-safe; some are terminal (bad input shape) and will fail the same way no matter how many times you re-run.
That means the event layer under an agent has to do more than a classical webhook service does:
- Deterministic replay — same input bytes while the payload is retained. Even if you change the transform later.
- Provider verification before the payload reaches the agent, so a forged event doesn't spend tokens.
- File relay — emails and forms bring attachments. The agent needs stable file references and refreshed signed URLs, not raw multipart parsing.
- Typed delivery destinations — the event can go to an HTTP endpoint, or on Pro+ to SQS, EventBridge, Pub/Sub, or S3-compatible object storage, while Pro+ event drains stream lifecycle telemetry to observability tools.
What you get when you don't build it yourself
We built Hooksbase as this event layer. HTTP, email, and form ingest on every tier; scheduled cron, payload transforms, provider packs, and bulk recovery on Starter+; typed non-HTTP destinations, alerts, and event drains on Pro+; and audit logs on Business+. The common delivery model still gives you programmable routing, delivery history, replay while payloads are retained, and DLQ recovery.
You don't need any of that to build your agent. You need it once your agent has to stay reliable.
If you're at week six of the arc — you know the one — start free and connect your first agent workflow. It takes about ten minutes.