No-code agent platforms are good now. You can build an agent that triages email, qualifies leads, or runs a multi-step tool-using workflow without writing code. OpenClaw, Hermes, Lindy, Relevance AI, Make, n8n, Zapier, Pipedream — the ecosystem is rich.
For a deeper take on automation platforms specifically, see Why automation platforms need an event layer in front.
What they all have in common: they nail the agent part. The authoring tools are excellent. The LLM integrations work. The tool library is wide.
What they also have in common: the event-plumbing part is thin. You get an inbound webhook. Maybe a form URL. Maybe an email trigger if you're lucky. But the moment your workflow needs something real — retries, replay, ordering, DLQ, provider verification, audit logs — you're off the platform and into custom glue.
This post is for people running into that wall.
What "built-in webhook receiver" usually means
A typical no-code agent platform's built-in webhook looks like this:
- A single endpoint URL per agent
- POSTs land as the trigger payload
- That's it
Provider-specific signature verification is usually limited or left to workflow logic. Retry, DLQ, replay, long-lived delivery history, and quota enforcement often live outside the built-in webhook trigger. That means a customer report like "the event never arrived" can turn into a manual investigation instead of a dashboard lookup.
For a prototype, that's fine. For real work, you lose events and never find out.
What production event infrastructure does
Contrast that with what an event layer built for reliability does:
| Capability | Built-in no-code webhook | Real event infrastructure |
|---|---|---|
| Signature verification | Generic auth or workflow-level checks | Starter+ provider packs for Stripe, GitHub, Clerk, Slack, Resend after Hooksbase ingest auth |
| Channels | HTTP only (maybe email on premium tiers) | HTTP + email + forms, with scheduled cron on Starter+ |
| Retries | Fixed exponential | Starter+ custom retry policy, Pro+ strict FIFO and throttling |
| DLQ + replay | Rarely present | Single-delivery replay on every tier, Starter+ bulk replay and DLQ re-drive, deterministic dispatch snapshots |
| Delivery history | Hours, maybe a day | 7–30 days depending on tier, plus 90 days of hourly summaries |
| Observability | Platform's own logs | Event drains to Axiom, Datadog, S3, OTLP HTTP |
| Audit logs | No | Yes on Business+, for regulated flows |
| Quota enforcement | Plan-wide | Per-project, per-webhook, with soft-cap overage |
Your no-code platform is the agent. An event layer underneath is the plumbing that makes the agent reliable.
How Hooksbase + OpenClaw fits
OpenClaw is a good example of the pattern. You build an agent in the OpenClaw builder. OpenClaw gives you a webhook URL that triggers the agent.
Instead of pointing your event sources directly at that URL, put Hooksbase in front. Sources that can send Authorization: Bearer <ingest secret> can call Hooksbase directly; dashboard-only providers may need a small verification forwarder first. Hooksbase enforces quotas, handles retries and replay, and dispatches the final event to the OpenClaw webhook.
Now your OpenClaw agent is production-ready without OpenClaw having to build the event layer themselves. And you can switch agent platforms later without rewiring every event source.
See the OpenClaw + Hooksbase landing page for the specific integration recipe.
When you need this
You don't need an external event layer for a demo. You probably don't need it for an internal tool where the people using it can just tell you when something broke.
You start needing it when:
- Real customers depend on the agent running when an event arrives
- Your agent handles money or regulated data
- You've got more than one place events originate from
- You've had at least one incident where "the event should have triggered the agent, but it didn't" and you couldn't answer why
- You're paying enough in LLM tokens that a forged event costs you real money
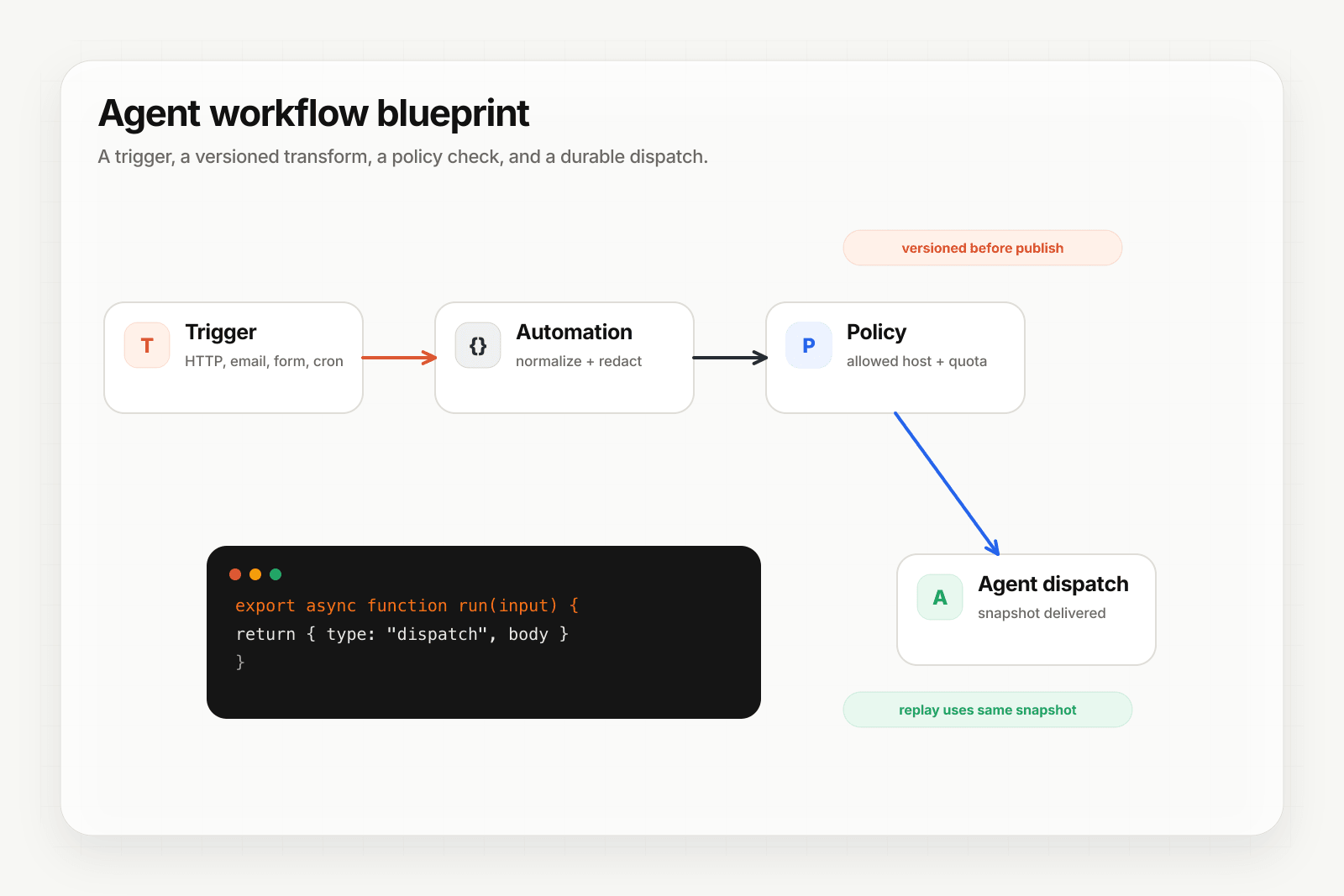
The two-layer pattern
The pattern we recommend:
- Layer 1: Event infrastructure. Receives, verifies, routes, retries, replays, observes. This is Hooksbase.
- Layer 2: Agent runtime. Receives the verified event, runs the agent logic, returns a response or emits an output. This is OpenClaw, Lindy, your custom code, whatever you're using.
Two layers. Clean separation. Your event layer stays the same when you switch agent platforms. Your agent platform stays the same when you add new event sources.
If your agent workflow is past the demo phase, that's the architecture to move toward. Start free and wire up a single webhook to see how it feels.