Event sourcing is a way of storing state where you keep every change as an immutable event in an append-only log, and you rebuild the current state by replaying those events from the beginning (or from a snapshot).
If you've ever wished you could "see what the database looked like at noon yesterday" without restoring a backup, event sourcing is the pattern that makes that trivial.
This guide explains event sourcing in plain English, when it's the right fit, what it costs you, and how it relates to deterministic replay for AI agents — which is event sourcing applied to event delivery instead of business state.
The pattern
Most systems store state directly:
users: { id: 42, name: "Octavia", status: "active" }
When something changes, you UPDATE the row. The previous state is gone.
An event-sourced system stores changes instead:
1. UserRegistered(id=42, name="Octavia", at=2026-01-01)
2. UserActivated(id=42, at=2026-01-05)
3. UserNameChanged(id=42, from="Octavia", to="Octavia Chen", at=2026-02-15)
The current state of user 42 is computed by folding these events:
state = events.reduce(apply, initial_state)
To know what user 42 looked like on 2026-01-10, fold events with at <= 2026-01-10. Free time travel.
Why bother?
Event sourcing trades query simplicity for three superpowers:
1. A complete audit trail by default. You can't lose history because history is the storage model. Compliance and debugging both benefit massively.
2. Time travel. Reconstruct any past state by folding events up to that point. Useful for debugging ("what did the system see when this happened?"), regulatory requests, and analytics ("what did our funnel look like last quarter, with the rules we had then?").
3. Replay against new logic. Change the apply function; replay the events; get a new state. Migrations, schema changes, and bug fixes all become "ship the new logic, replay" instead of "write a migration script."
The trade-offs:
- Querying current state is more expensive (fold events; usually cached via projections or snapshots).
- Storage grows without bound (mitigated by snapshots).
- Schema evolution is real work (events are immutable, so changing their shape requires versioning).
For most CRUD apps, the trade-offs aren't worth it. For domains where audit, time travel, or replay are first-class needs — finance, healthcare, supply chain — they often are.
Snapshots and projections
Two patterns make event sourcing practical at scale.
Snapshots: periodically, you save the current state of an entity ("user 42 as of event 1,000"). To compute current state, load the latest snapshot and fold only the events since. Bounds the cost of state reconstruction.
Projections: a projection is a read-optimized view of the event log. You consume events and update a queryable database (the "projection store"). When the projection is wrong, you rebuild it from the event log. Multiple projections can coexist for the same data — current state, time-series analytics, search index, etc. — each tuned for its query pattern.
This is where event sourcing pairs naturally with event-driven architecture: the event log is the source of truth; projections subscribe to it.
Event sourcing vs the event log in your message broker
A confusing point: many teams say "we have event sourcing" because they put events in Kafka. That's not event sourcing in itself — it's an event log. Event sourcing is the choice to make that log the source of truth for application state, not just a transport mechanism.
If your application still has a database that's the canonical state and Kafka is downstream of it, you have an event-driven architecture, not event sourcing. If your database is rebuildable from the event log and the event log is what you'd restore from after a disaster, you have event sourcing.
The distinction matters because the engineering investment is different. An event log on the side is light. Making the event log the source of truth requires schema versioning, snapshot strategies, projection rebuilds, and a query layer that doesn't depend on the side-database.
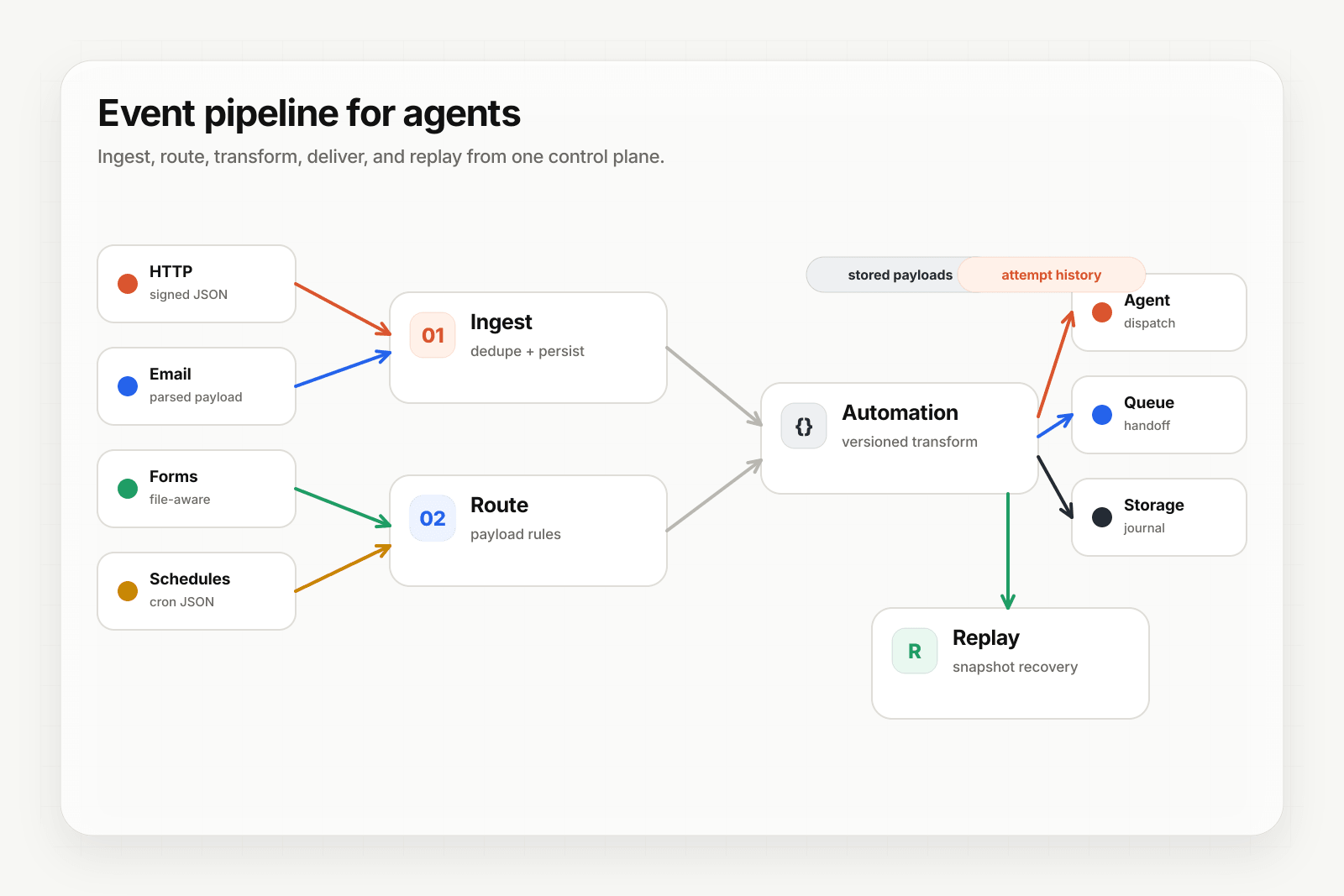
Where deterministic replay for AI agents fits
This is the relevant tie-in for anyone running agents.
Most AI agent systems aren't event-sourced for business state. They use a normal database. But the delivery layer in front of the agent benefits massively from event-sourcing-like properties:
- Every retained event the agent processed keeps the original payload.
- The transformation applied to the event is also stored (the dispatch snapshot).
- You can replay retained events with the original input and current agent logic.
This is what Hooksbase's deterministic replay does. The relay isn't a full event-sourcing system for your business state — that's still your application's choice. But for the event delivery layer specifically, the agent-friendly version of event sourcing is exactly what you want: persisted raw payloads, persisted dispatch snapshots, replay retained deliveries against the agent's current behavior.
When the agent's prompt changes and you want to know how it would have handled last week's failures, you don't need a full event-sourced backend. You need the relay to have stored the events you care about. That's a much smaller commitment with a lot of the same upside.
When event sourcing is the right fit
Strong fit:
- You need a complete audit log by regulation (finance, healthcare).
- You expect to need to reconstruct past state for debugging or investigation.
- Your business has natural events that already have meaning to the domain (orders, payments, ledger entries).
- You want to evolve read models without disturbing the write path.
Weak fit:
- Simple CRUD apps where the audit trail doesn't matter.
- Heavy ad-hoc query patterns over the latest state.
- Small teams that don't have the engineering bandwidth for projection rebuilds and schema evolution.
Most teams should not adopt full event sourcing for their primary state. Most teams should adopt event-sourcing-style properties for their event delivery layer (persisted events, replay, an audit trail of attempts) — which is what a webhook relay gives you for free.
Where to go next
- Event-driven architecture for AI agents for the broader EDA context
- Deterministic replay for agents for replay applied to agent delivery
- What is a message queue? for the queue-vs-event-log distinction
- Routing, transforms, and replay for AI agents for the relay-side patterns