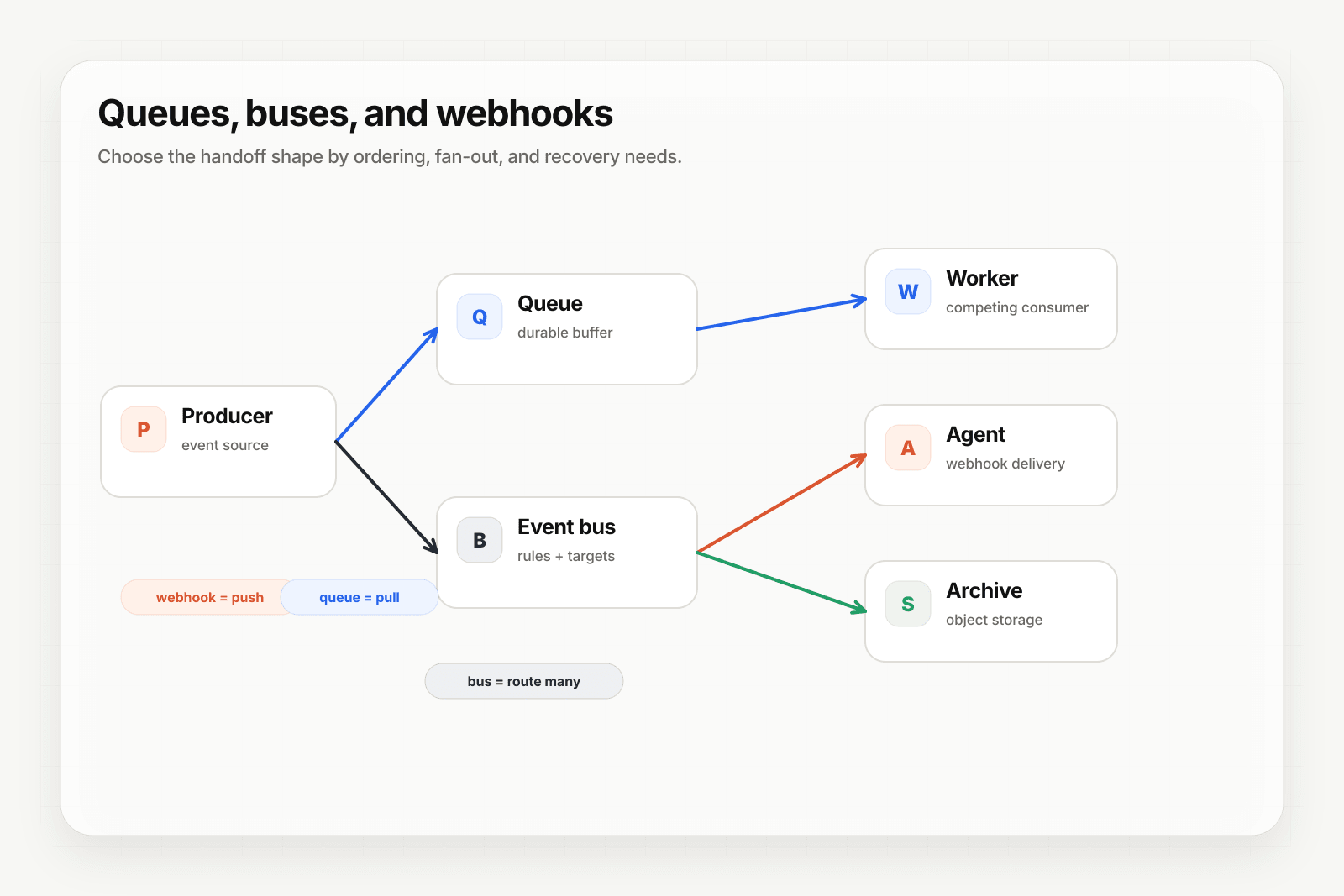
A message queue is a durable buffer between two systems where one (the producer) puts messages in and another (the consumer) takes them out. The queue holds messages until they're consumed, decouples producer speed from consumer speed, and survives outages of either side.
If you've used SQS, RabbitMQ, Kafka, Redis Streams, or BullMQ, you've used a message queue. They're one of the foundational building blocks of distributed systems. They're also frequently the wrong tool for what people reach for them to do.
This guide covers how queues work, when they're the right fit, and when webhooks (with a relay in front) beat them.
How does a message queue work?
The basic flow:
- Producer writes a message to the queue. Doesn't wait for it to be consumed.
- Queue holds the message durably. Survives broker restarts, consumer outages.
- Consumer reads the message (pulls or is pushed to), processes it, acknowledges.
- If the consumer fails or doesn't ack within a visibility timeout, the message becomes available again for retry.
- After a configurable number of failed attempts, the message moves to a dead-letter queue (DLQ) for inspection.
The queue is "in the middle" — neither the producer nor the consumer needs to know about the other. This decoupling is what makes queues useful.
What problems does a message queue solve?
Three big ones:
1. Speed mismatch. Producer is fast (a webhook receiver getting 10,000 events per minute). Consumer is slow (an email sender doing 100 emails per minute). Without a queue, the producer either blocks or drops events. With a queue, the producer continues and the consumer drains at its own pace.
2. Durability across outages. Consumer is down for an hour. Without a queue, events sent during that hour are lost. With a queue, they accumulate and are processed when the consumer comes back.
3. Fan-out to multiple consumers. One event needs to reach a payment system, an analytics pipeline, an email sender, and a CRM sync. Without a queue (or pub/sub), the producer needs to know all four. With a queue (or topic with multiple subscribers), the producer publishes once.
Common message queue implementations
The most common queue systems and where they fit:
- AWS SQS — managed, simple FIFO and standard queues. Good default for most use cases.
- AWS EventBridge — event-routing layer that fans out to many AWS services. Less of a queue, more of a pub/sub bus.
- GCP Pub/Sub — Google's managed pub/sub. Similar feature set to EventBridge.
- Apache Kafka — high-throughput log-structured queue. The right tool when you need replay, ordering at scale, or multiple consumer groups reading the same data independently.
- RabbitMQ — flexible broker supporting multiple messaging patterns. The right tool when you need fine-grained routing rules.
- Redis Streams / Redis Pub-Sub — lightweight, fast, simple. The right tool for in-memory or low-latency cases.
- BullMQ / Sidekiq / Celery — application-level queues built on Redis or other backends. The right tool when "queue" is really "job runner."
The choice depends on throughput, durability requirements, ordering needs, and whether you want managed or self-hosted.
Webhooks vs message queues
This is where most teams get confused. Webhooks and queues are often presented as alternatives. They're not — they solve overlapping but distinct problems.
| Webhook | Message queue | |
|---|---|---|
| Boundary | Cross-organization (you to your customer) | Within your system or trusted boundary |
| Transport | HTTP POST | Custom protocol or HTTP |
| Delivery | Push (sender invokes receiver) | Pull or push depending on broker |
| Consumers | Usually one per webhook URL | One or many |
| Operating burden | Sender's | Yours (broker ops) or vendor's (managed) |
Use webhooks when:
- You're delivering events to a different organization (you don't operate their system).
- The receiver is reachable via HTTP and HTTP semantics fit (one POST per event, 2xx ack).
- You want a simple, well-understood interface that any HTTP server can implement.
Use a queue when:
- Producer and consumer are within your trust boundary.
- You need fan-out to many consumers reading the same event independently.
- You need strict ordering, replay from a specific offset, or high throughput beyond what HTTP delivery comfortably handles.
- You're already operating a broker and adding another producer is cheap.
Use both when: events come from outside (webhook), then fan out internally (queue). This is the canonical production pattern. The webhook delivers the event reliably; the queue distributes it to internal consumers.
When webhooks beat message queues
Three cases where reaching for a queue is over-engineering:
1. Delivering to a single internal consumer that's HTTP-reachable. A queue adds a hop and an operational dependency. A webhook (with a relay in front for retries and replay) does the same job with less infrastructure.
2. Delivering to an external partner. Your partner doesn't want to consume from your SQS. They want a webhook. Build the webhook layer.
3. AI agent triggers. Agents are HTTP services. A webhook with retries and replay (a relay) is the right primitive. Adding SQS in the middle adds latency and complexity without solving a problem.
The opposite mistake — using webhooks for high-throughput internal fan-out — also exists. Webhooks at 10K events per second across 5 internal consumers is what queues are for.
When a relay in front of webhooks is the right answer
A webhook relay (like Hooksbase) is a queue-like component built specifically for HTTP delivery. It gives you the queue-shaped properties — durability, retries, dead-letter handling, replay — at the boundary where events come from outside.
For agent systems specifically, the pattern that ships:
- Webhook in — a source that can attach the Hooksbase bearer secret posts to the relay directly; dashboard-only providers may go through a verification forwarder first.
- Routing in the relay — programmable rules decide which destination gets the event.
- Webhook out — relay POSTs to your agent endpoint with retries.
- Optional queue inside — if your agent has multiple downstream consumers (analytics, audit, CRM), an internal queue handles the fan-out.
This is the "best of both" architecture: webhooks at the cross-system boundary where they're the right tool, queues inside your trust boundary where they shine.
Where to go next
- Webhooks vs APIs: when to use each for the push-vs-pull decision
- Event-driven architecture for AI agents for the broader pattern
- Event sourcing in plain English for the related event-log pattern
- How to build an AI agent for the practical agent build path