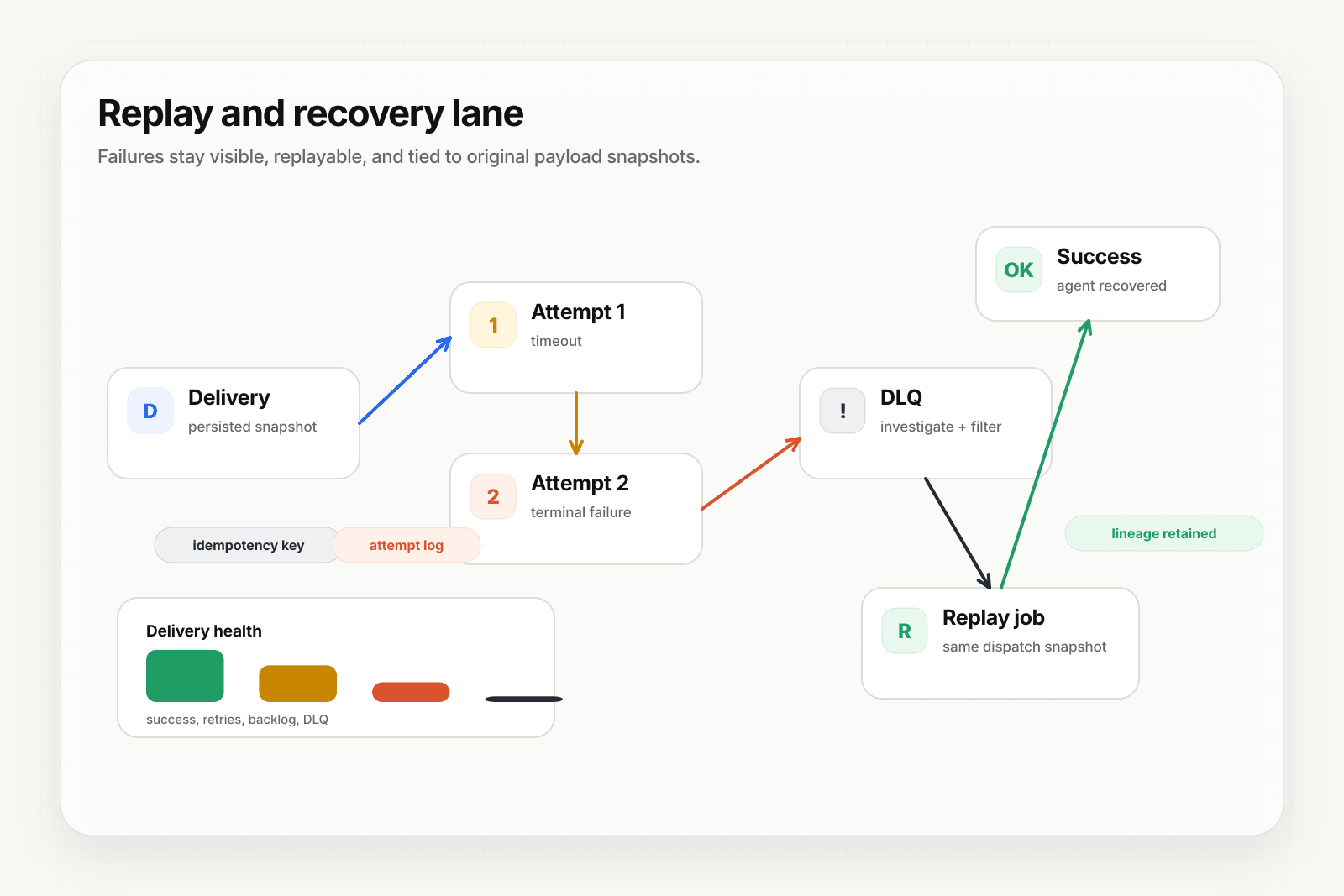
A dead-letter queue (DLQ) is a holding area for messages that couldn't be processed successfully — events that exhausted their retry budget, hit a terminal error, or got stuck in a way that retries can't fix. Without a DLQ, those events disappear silently or block the rest of the queue. With one, they're queryable, inspectable, and recoverable.
Every webhook system at scale has a DLQ — even if it's just a database table called failed_events. This guide covers how DLQs work, how to design them well, and the recovery patterns that ship in production.
What ends up in a DLQ?
A DLQ catches three kinds of failures:
1. Exhausted retries. A delivery has been attempted N times and still fails. After N, the system gives up retrying and moves the event to the DLQ instead of looping forever.
2. Terminal delivery errors. Some outbound failures don't deserve retry. Bad downstream input shape, business-logic rejection, or a non-retryable destination response can go straight to the DLQ on the first occurrence. Provider signature verification failures happen before persistence in Hooksbase and are rejected rather than dead-lettered.
3. Poison messages. A specific event's payload triggers a bug in the consumer that crashes it every time. Without a DLQ, the queue stays stuck on this one event. With one, it moves to the DLQ and the queue keeps moving.
The first category is by far the most common. Tuning the retry budget so the right things end up in the DLQ — not too soon, not too late — is most of the design work.
How a DLQ fits in the delivery flow
The standard flow with a DLQ:
Event arrives → consumer attempts → fails → retry queue with backoff
→ after N retries → DLQ
→ after terminal delivery error → DLQ
Every webhook relay or message broker has some version of this. SQS has a DLQ as a redrive policy on the source queue. Kafka has the same pattern via consumer-side handling. Webhook relays like Hooksbase move terminally-failed deliveries to a DLQ tier with their own dashboard, querying, and re-drive operations.
Designing the retry budget
How many retries before something goes to the DLQ? The honest answer: it depends on your consumer's reliability profile and how time-sensitive the event is.
A starting framework:
| Consumer reliability | Recommended retry budget | Total time before DLQ |
|---|---|---|
| Highly reliable internal service | 3-5 retries with exponential backoff | ~5-15 minutes |
| External API you depend on | 5-8 retries with exponential backoff | ~30-90 minutes |
| Customer-facing receiver | 8-12 retries with exponential backoff | ~6-24 hours |
The key insight: retries should bias toward generous, not conservative. A failed delivery in the DLQ is recoverable. A successful delivery you abandoned isn't. Err on the side of more retries unless cost or downstream load is a hard constraint.
The exponential backoff matters too. A typical schedule: 30s, 1m, 5m, 15m, 1h, 4h, 12h, 24h. The early retries catch transient blips; the later ones catch longer outages.
What to put in the DLQ entry
A DLQ entry needs enough context for recovery. The minimum:
- The original event — exact bytes, not parsed
- All attempt records — when, what response, what error
- The terminal error — the specific reason it gave up
- Retry budget consumed — how many attempts were made
- The destination it was trying to reach — URL, transform applied, headers
Without all of this, "let me see why it failed" becomes "let me reconstruct what happened from logs." The DLQ exists to make recovery fast; it should contain everything needed to act.
Recovery patterns
Five patterns show up in production DLQ workflows.
1. Manual inspect-and-replay
Engineer opens the DLQ dashboard, looks at a failed event, decides to replay it. Works for low-volume DLQs (a few entries per day).
2. Bulk re-drive after a fix
A bug deploy caused a cluster of failures. Engineer ships the fix, then bulk-replays everything in the DLQ that matches a filter (specific destination, date range, error type). In Hooksbase, that bulk path is Starter+; single re-drive remains available on every tier. The relay sends each event back through normal delivery; what succeeds clears from the DLQ, what fails again accumulates with new attempt records.
3. Automated re-drive on schedule
The DLQ has known transient errors (specific 503s, specific timeouts) that resolve themselves. A scheduled job re-drives DLQ entries matching those error patterns periodically; what succeeds clears, what fails again is left for human review.
4. Escalation path
Some terminal errors need human attention immediately (regulatory events, payment failures over a threshold). The DLQ flow notifies on-call when these specific events arrive, in addition to leaving them in the DLQ for normal recovery.
5. Backfill from source
For events past the relay's payload retention, recovery means querying the upstream source's API for the original event and replaying. Specific to providers that have an Events API (Stripe, GitHub, Shopify) where past events can be re-fetched.
Most production teams use a mix: scheduled re-drive for known transients, manual inspect-and-replay for novel failures, escalation for high-stakes failures, bulk re-drive after fixes, backfill for old events.
DLQ alerting
A DLQ that nobody looks at is a silent failure. The minimum alerting:
- Accumulation rate alert — fire when DLQ grows by more than X events in Y minutes (catches sudden spikes).
- Stale-entry alert — fire when DLQ entries older than X hours remain unaddressed (catches forgotten DLQs).
- Per-destination DLQ alert — fire when a specific destination starts contributing disproportionately (catches a single broken destination).
Hooksbase covers this surface with Pro+ alert families such as DLQ accumulation, terminal-failure spikes, and destination-health degradation. Pair them with event drains to your existing observability stack so DLQ entries flow into the same dashboards as the rest of your agent telemetry.
DLQ vs unbounded retry: pick one
Some teams retry forever instead of having a DLQ. This is a mistake at scale. Unbounded retries:
- Mask real problems (the destination is permanently broken; you'll never notice)
- Waste compute and money (retrying terminal failures forever)
- Block forward progress (if the queue is FIFO, the stuck event holds up everything behind it)
Pick a finite retry budget. Pick a DLQ. Watch the DLQ.
Where to go next
- The complete guide to idempotency keys for the dedup primitive that makes safe replay possible
- Deterministic replay for agents for the replay primitive
- Recover failed agent events with DLQ and replay for the practical Hooksbase walkthrough
- Event-driven architecture for AI agents for the broader pattern