Cloudflare Workers are a serverless compute platform that runs code at Cloudflare's edge — over 300 locations, V8 isolates instead of containers, and no container cold-start path. Coupled with Cloudflare's storage primitives (D1 for SQL, R2 for object storage, Durable Objects for stateful coordination, Analytics Engine for metrics), they're a complete platform for building stateful HTTP services.
We built Hooksbase on Workers. This piece covers why that was the right choice for webhook infrastructure specifically, the architecture we ended up with, the constraints worth knowing about up front, and where Workers are the wrong tool.
Why Workers fit webhook infrastructure
Three properties matter for any service that ingests, processes, and delivers webhooks at scale.
1. No container cold starts in the delivery path. A webhook receiver has to ack providers quickly; Slack Events API requests, for example, must get a 2xx within 3 seconds. Avoiding a container cold-start path matters when retry storms hit and your handler is suddenly receiving 10x normal volume.
2. Edge proximity. Workers run close to the request source. A Stripe webhook from a customer in Europe routes to a European Worker, not back to us-east-1. Lower latency on ingest means faster ack, fewer retries, less time the provider sees your endpoint as slow.
3. Integrated storage. Workers have first-class access to D1 (SQLite), R2 (S3-compatible object storage), Durable Objects (stateful single-instance coordination), Analytics Engine (high-cardinality metrics), and Queues. All accessible via bindings — no network hops to a separate database, no auth round-trips. For a webhook system that needs durable persistence, atomic counters, and fast metric aggregation, the integration is significant.
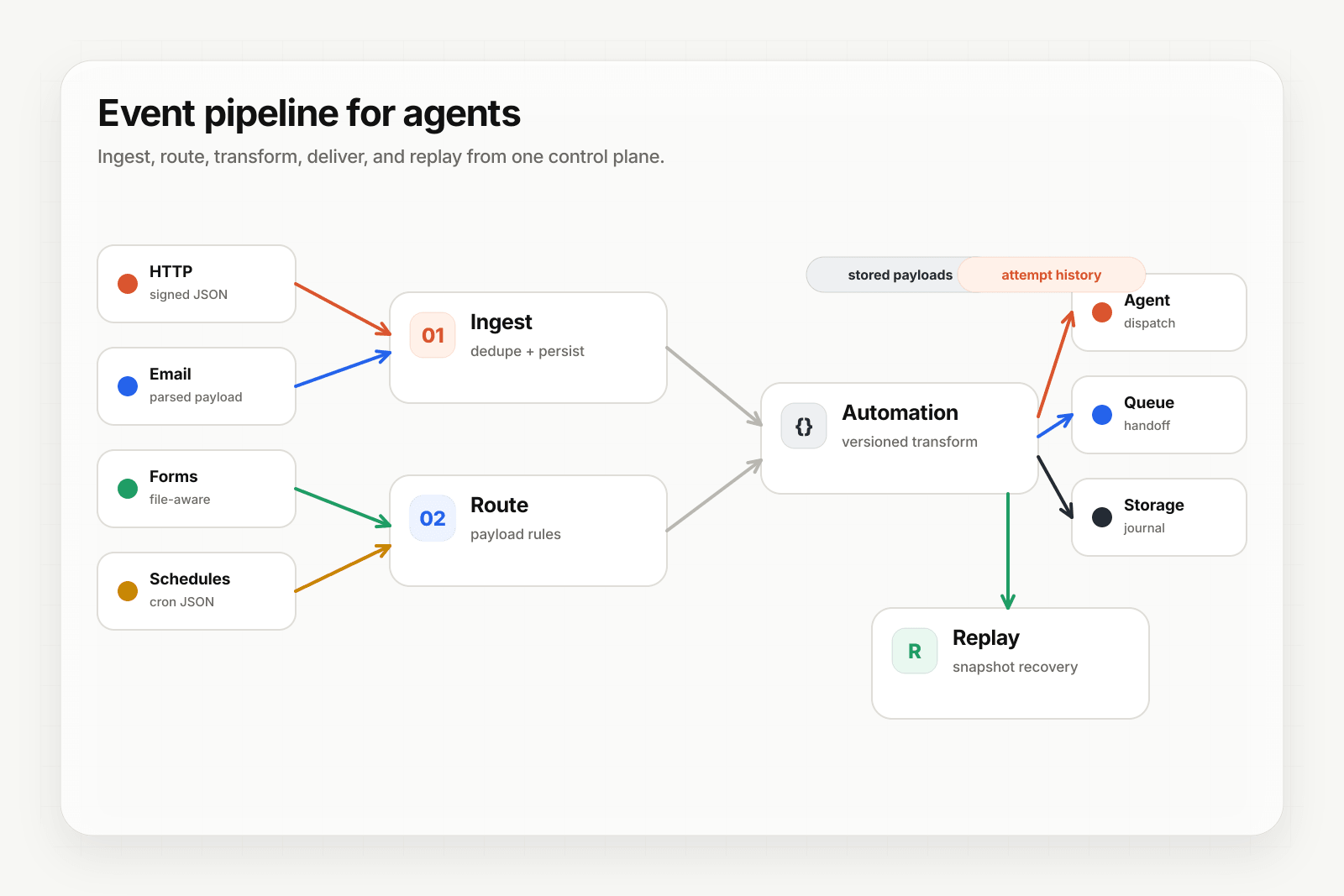
The Hooksbase architecture in one diagram
What we ended up with:
Provider / email / form / cron
│
▼
API Worker (Hono on Workers)
│
├── D1 control-plane (config, quotas, secrets, auth)
├── D1 data-plane (deliveries, attempts, payloads — sharded across 256 virtual shards)
├── R2 (raw payloads + dispatch snapshots)
├── Durable Objects (per-webhook sequencing, quota buckets, replay dedup)
├── Analytics Engine (delivery event metrics)
└── Queues (dispatch jobs, bulk operations)
│
▼
Web Worker (TanStack Start dashboard)
│
▼
Customer endpoints / SQS / EventBridge / Pub/Sub / S3
Two Workers — API for ingest and delivery, Web for the dashboard — backed by a small set of shared storage primitives. The split lets the dashboard evolve without touching the delivery hot path; it also lets each Worker have its own bindings, deployment cadence, and rollback story.
Where Durable Objects fit (and where they don't)
Durable Objects (DOs) are the trickiest Cloudflare primitive to reason about. Each DO is a single-instance, single-threaded actor with strongly-consistent storage. Think "named singleton with its own SQLite."
We use DOs for three things, all of them serialization problems that need a consistent in-memory state:
- Per-webhook delivery sequencing — the
WebhookCoordinatorDO ensures FIFO ordering for webhooks configured for strict FIFO mode. Each webhook has its own DO instance. - Per-project quota token buckets — the
ProjectQuotaCoordinatorDO enforces ingest rate limits with strict consistency (so two parallel requests can't both pass the limit check). - Replay dedup — the
ReplayCoordinatorDO serializes concurrent replay-creation requests for the same source delivery so we don't accidentally create duplicate child deliveries.
What we don't use DOs for: anything that doesn't need single-instance consistency. The bulk of webhook state lives in D1 and R2, where the access patterns are query-shaped and the consistency requirements are weaker. DOs are expensive (per-request invocation overhead) and shouldn't be the default; reach for them only when serialization is the actual problem.
See Durable Objects for per-tenant webhook state for the deeper architectural take.
D1: a sharded SQLite per webhook
D1 is Cloudflare's managed SQLite. Each D1 database is bounded in size, so Hooksbase splits storage two ways:
- Control-plane — one D1 database holding slow-changing data: project config, quotas, signing secrets, user accounts. Single database, queryable by all Workers.
- Data-plane — many D1 databases, sharded by virtual shard ID computed from the project ID (FNV-1a hash mod 256). Fast-growing tables live here: deliveries, attempts, payload metadata, idempotency keys. The architecture supports up to 256 physical D1 databases.
The shard key is project ID. A given project's deliveries always land in the same data-plane database, which keeps queries local to one shard. Cross-shard queries are rare in normal operation — most reads are scoped to a single project.
R2: payload storage outside the database
Webhook payloads can be hundreds of KB. Storing them in D1 would inflate the database; storing them externally is cheaper and keeps queries fast.
Hooksbase persists two things to R2:
- Raw payloads — keyed by
payloads/{webhook_id}/{delivery_id}. Shared across replays so a replay re-uses the original bytes. - Dispatch snapshots — keyed under
dispatch-payloads/.... The transformed payload at the time of dispatch, persisted so replays remain correct even after the transform config changes.
Together these enable deterministic replay — every retained delivery can be re-run with the original input even if downstream config has evolved.
What Workers can't do (and why it's mostly OK)
Workers have real constraints. The honest list:
- CPU limits per request. Long synchronous compute doesn't fit. For webhook ingest and delivery, this is not the constraint that matters — the work is I/O-bound.
- No persistent connections to external systems (no holding TCP connections open across requests). Each invocation makes its own connections. Fine for HTTP-based outbound; not fine for things that need long-lived connections (gRPC streams, raw TCP).
- Limited language support — JavaScript, TypeScript, and WebAssembly. No Python, Go, or Rust running natively (though Rust compiled to Wasm works).
- Memory limits per request — not an issue for webhook payloads under typical caps; could be for larger workloads.
- No file-system persistence between invocations. Storage has to be R2, D1, KV, or DO storage.
For webhook infrastructure specifically, none of these are dealbreakers. The work is short, I/O-heavy, and HTTP-shaped — exactly what Workers are designed for.
When Workers are the wrong tool
Workers are not the right answer for:
- Long-running compute (ML inference longer than a few seconds, batch processing). Use a different platform.
- Stateful streaming (video transcoding, persistent WebSocket clusters with rich session state). Workers can do WebSockets but the model is different from a long-lived server.
- Tight integration with non-Cloudflare services that require persistent connections (Postgres with connection-pooling assumptions, Kafka clients with long-lived consumer connections). Workers can call these but the model is request-per-call, not persistent client.
- Existing codebases not in JavaScript/TypeScript/Wasm. Porting is real work.
For everything else — HTTP APIs, ingest endpoints, edge transformations, stateful coordinators that don't need persistent connections — Workers are competitive with anything else and often better.
Where to go next
- Durable Objects for per-tenant webhook state for the DO patterns we use
- Event infrastructure for AI agents for the architectural argument applied to agents
- Deterministic replay for agents for the R2-backed replay pattern
- Routing, transforms, and replay for AI agents for the routing model