Agentic AI is software that perceives its environment, decides what to do, and takes action toward a goal — without a human prompting every step. Where a chatbot waits for input and returns text, an agentic system reads from the world, reasons about it, and acts on a loop until the goal is met or it gives up.
That definition is doing a lot of work, so let's break it down — and then look at where agentic AI tends to fall apart once it leaves the demo.
How does agentic AI work?
An agentic system runs a loop:
- Perceive — receive an event from the world: an HTTP webhook, an email, a form submission, a scheduled trigger, a tool result.
- Decide — feed that event (plus relevant context and memory) to an LLM that picks the next action.
- Act — call a tool, send a message, write to a database, hand off to another agent, or stop.
- Loop — observe the result, update state, decide again.
The "agentic" part is the autonomy of step 2 and 3. Classical software does what it's told. Agentic software decides what to do based on the goal, the context, and the latest input. It can refuse, re-plan, retry, or escalate.
Agentic AI vs an AI chatbot
A chatbot is reactive. You type, it answers, you type again. The user drives the loop.
An agentic system is autonomous. The world drives the loop. A new email arrives, a webhook fires, a cron tick happens, a tool returns — the agent reacts on its own. It might run for thirty seconds or thirty minutes. It might call ten tools or none. It might decide the work is done, or escalate to a human.
This shift — from user-driven to world-driven — is the entire point of agentic AI. It's also the reason so many demos that look great in a notebook fall over in production.
Examples of agentic AI
Concrete examples that ship today:
- A support triage agent reads incoming emails, classifies the issue, looks up the customer in a CRM, drafts a reply, and either sends it or hands off to a human.
- A revenue ops agent watches Stripe webhooks for failed payments, checks the subscription history, attempts a card update flow, and notifies the account owner if the customer churns.
- A lead enrichment agent receives form submissions, hits enrichment APIs, scores the lead, routes it to the right SDR, and writes the decision back to the CRM.
- A release agent consumes GitHub webhooks on every PR merge, runs the changelog generator, drafts a release note, posts to Slack, and updates the docs site.
- A scheduled monitoring agent wakes up every fifteen minutes, queries production metrics, decides if something needs attention, and pages on-call only when it does.
Notice the pattern: in every case, events from the outside world drive the loop. The agent itself is a small piece of code calling an LLM. The hard part is everything that brings events in and ships results out.
Where agentic AI breaks in production
The agent works fine in a notebook. The first customer signs up. Then:
- Events drop silently. A webhook returns a 503 once and is never retried. The agent never runs. The customer asks why nothing happened.
- Retries are unsafe. The LLM is non-deterministic. Re-running a failed event can charge a card twice, send two emails, or write conflicting state.
- There's no replay. The agent timed out yesterday. The original payload is gone. You can't re-run it without asking the customer to redo their action.
- Failures aren't observable. Was the event received? Did it reach the agent? Did the agent fail or succeed? Where did the result go? Without a delivery history, every failure becomes a forensic exercise.
- Multi-channel ingest is painful. Your agent gets triggered by webhooks, emails, forms, and cron — each with its own parser, signature scheme, and retry semantics. Each channel becomes its own pipeline.
These aren't agent problems. They're event-infrastructure problems. The agent is doing what it was asked. The layer underneath is the layer that's failing.
What agentic AI needs to be reliable
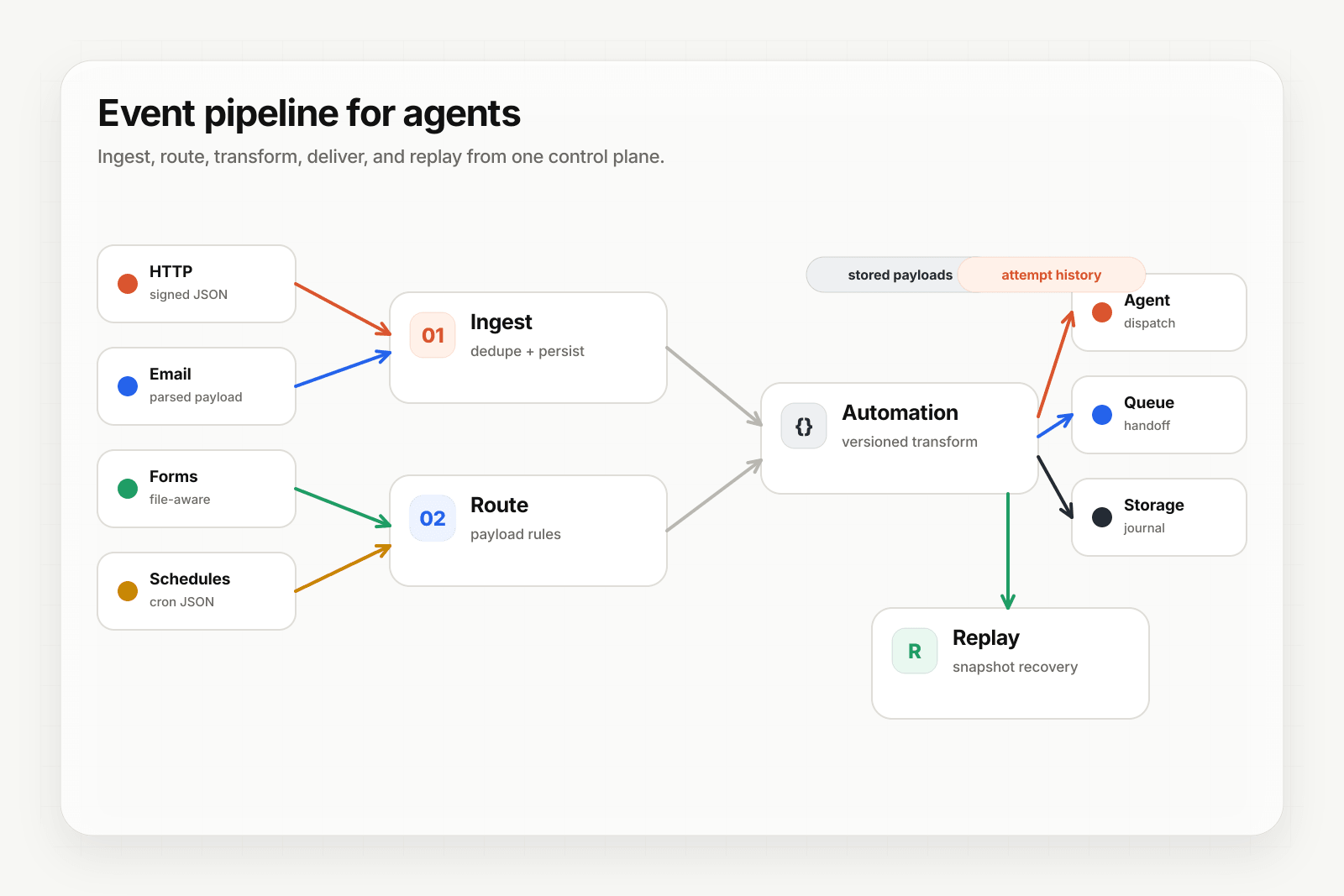
A production-grade agentic system needs an event layer that does five things the agent itself can't do:
- Reliable ingest from every channel the agent reacts to — HTTP, email, forms, scheduled cron — funnelled into one delivery model.
- Provider verification for supported providers so a forged webhook doesn't spend tokens or trigger a side effect.
- Deterministic replay so you can re-run retained events with the exact same inputs even after you change the prompt or the transform.
- Delivery guarantees — retries with backoff, idempotency, strict ordering when the agent has to process events in sequence, throttling when it's slow.
- Observability and recovery — delivery history, attempt detail, DLQ for terminal failures, replay for transient ones, alerts when something's drifting.
This is the part teams underestimate. It's also the part that doesn't go away — every new agent, every new provider, every new channel needs the same plumbing.
Agentic AI and event infrastructure
We built Hooksbase as the event layer for agents. Four ingest channels with scheduled cron on Starter+, programmable routing, Starter+ payload transforms, Pro+ typed outbound destinations, Starter+ verified provider packs, tiered delivery history and replay, DLQ recovery with Starter+ bulk operations, Pro+ alerts and event drains, and Business+ audit logs.
You don't need any of it to build an agent. You need it once your agent has to stay reliable.
Next reading: What is an AI agent? for the technical definition, or How to build an AI agent with reliable event triggers if you're shipping one this week.