Amazon SQS (Simple Queue Service) is AWS's managed message queue. Producers send messages to a queue; consumers poll the queue to receive them; AWS handles the durability, scaling, and infrastructure. It's the default queue choice for teams that already live in AWS.
This guide covers what SQS is, the difference between Standard and FIFO queues, when SQS is the right tool, and how webhook events end up in SQS through forwarders.
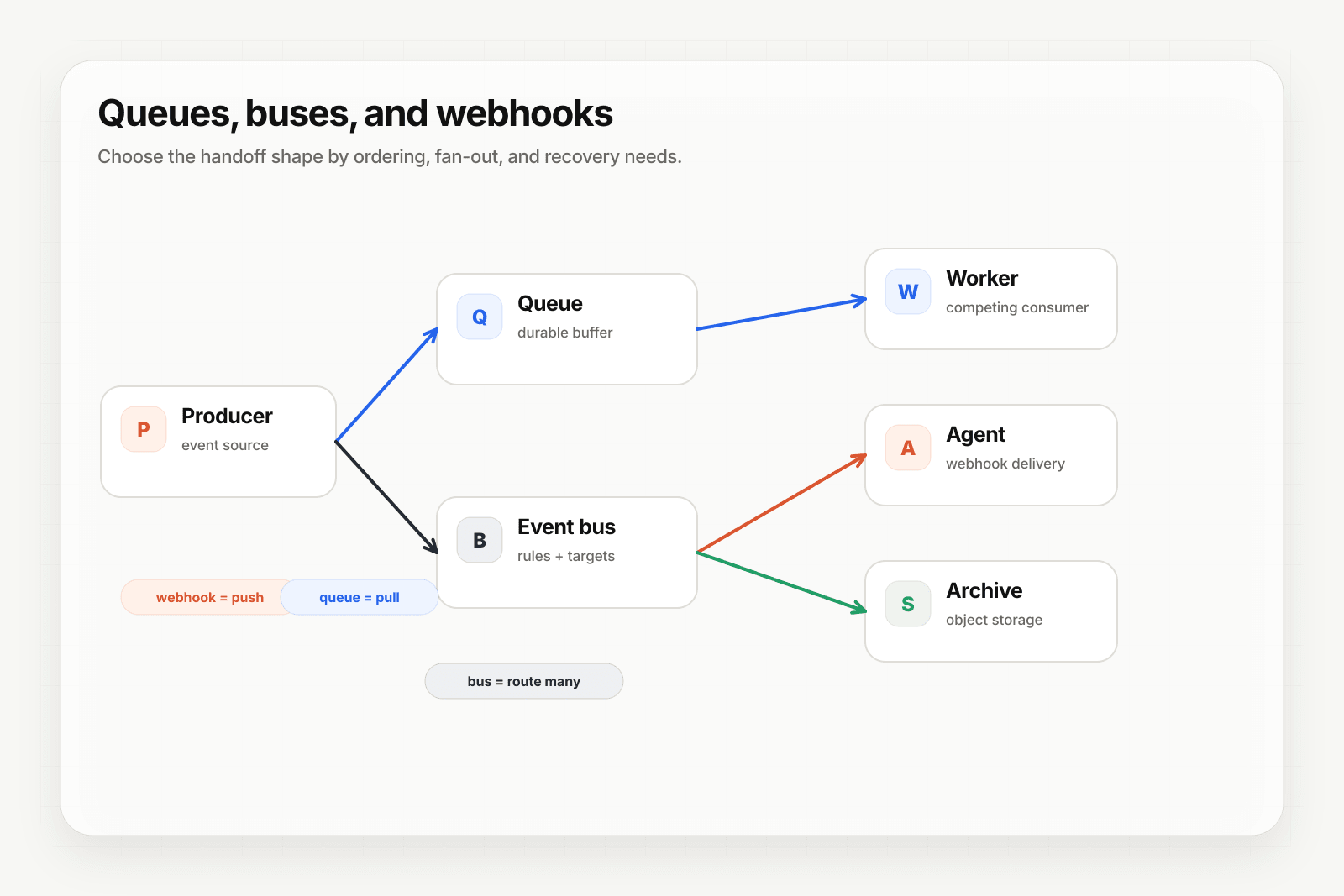
How does SQS work?
SQS is pull-based: producers send messages, consumers poll. The basic flow:
- Producer calls
SendMessageto put a message on the queue. Returns immediately. - SQS stores the message redundantly across availability zones.
- Consumer calls
ReceiveMessageto pull messages (typically using long polling). - Consumer processes the message, then calls
DeleteMessageto acknowledge. - If consumer doesn't delete within the visibility timeout, the message becomes available again for another consumer to pick up.
The model is at-least-once delivery. Consumers will see duplicates and need to handle them via idempotency.
Standard queues vs FIFO queues
SQS comes in two flavors with significantly different guarantees.
Standard queues:
- Nearly unlimited throughput
- At-least-once delivery (duplicates possible)
- Best-effort ordering (events can arrive out of order)
- Lower cost
FIFO queues:
- Lower throughput than Standard unless high-throughput FIFO is configured
- Exactly-once processing within a deduplication window
- Strict ordering within a message group
- Slightly higher cost
The trade-off: order and exactly-once cost throughput. Use FIFO when ordering matters (subscription state changes, financial transactions); use Standard when it doesn't (fan-out notifications, analytics events).
When is SQS the right tool?
SQS shines when:
- You're already in AWS and don't want to operate a broker
- Producer and consumer are both within your AWS account
- You need durability and at-least-once delivery without running infrastructure
- You want simple polling semantics with managed scaling
SQS is the wrong tool when:
- You need pub/sub fan-out to multiple independent consumer groups (use SNS in front, EventBridge, or Kafka)
- You need to replay messages from an arbitrary point in history (use Kafka)
- You need fine-grained routing rules (use EventBridge or RabbitMQ)
- You need cross-cloud or multi-region with active-active producers (use Kafka or your cloud's equivalent)
For most "I need a queue" needs in AWS, SQS is the right default. For everything beyond that, look at EventBridge, SNS, Kinesis, or Kafka.
SQS limits worth knowing
The constraints that bite teams the first time they hit them:
- Message size: 256 KB max body. Larger payloads need to be stored elsewhere (S3) and referenced by URL.
- Retention: 14 days max. Messages older than that disappear.
- Visibility timeout: 12 hours max. Long-running consumers need to extend the timeout via
ChangeMessageVisibility. - In-flight messages: Standard queues have an approximate 120,000 in-flight message limit; FIFO throughput and in-flight behavior are quota-sensitive, so check the current AWS quota page for your region and queue mode.
These aren't dealbreakers for most workloads, but they're worth knowing before you architect around SQS.
How webhook events get into SQS
Webhook events come from the outside world (Stripe, GitHub, etc.) and SQS lives inside your AWS account. The bridge between them is a forwarder.
The simplest forwarder is a Lambda function with a Function URL or behind API Gateway: the Lambda receives the webhook, validates it, and calls SendMessage to put it on SQS. Your downstream consumers pull from SQS as normal.
This works. It also leaves you owning:
- The webhook receiver (URL, signature verification per provider)
- Retry logic when SQS
SendMessagefails (rare but possible) - A retained log of received webhooks for audit and replay outside SQS's 14-day retention
- Error paths when the Lambda itself fails (DLQ for the Lambda, not just for SQS messages)
A webhook relay like Hooksbase can sit in this position instead. Sources that can send Hooksbase ingest auth call the relay directly; dashboard-only providers can go through a small verification forwarder. Hooksbase persists accepted events and dispatches to SQS as a Pro+ typed destination. You skip building the Lambda receiver, you get retained payload storage independent of SQS retention, and you get the relay's reliability primitives (retries, DLQ, replay, delivery history) on top of SQS's.
SQS as a destination for a webhook relay
When SQS is the destination of a webhook relay, the pattern looks like:
Stripe / GitHub / form / email → Hooksbase → SQS → your consumers
Hooksbase ingests the event, optionally transforms it, and calls SendMessage on the SQS queue. Your existing AWS-side consumers don't change — they keep polling SQS. The only thing that changes is what feeds the queue.
This split is usually the right architecture: webhooks at the cross-system boundary (where HTTP is the right protocol), SQS inside your AWS boundary (where the team already operates it).
Where to go next
- What is a message queue? for the broader queue concept
- What is EventBridge? for AWS's pub/sub layer
- Kafka vs SQS for webhook fan-out for when each fits
- Event-driven architecture for AI agents for the broader pattern