The classic question for teams building event-driven systems on AWS or with self-hosted infrastructure: should webhook events fan out through Kafka or through SQS?
Both work. They have meaningfully different trade-offs and the right answer depends on what's downstream. This guide covers when each fits, the failure modes of each, and a third option most teams should consider before reaching for either.
The TL;DR
- Kafka is right when you need replay, multiple independent consumer groups, ordered partitioned streams, and you have a team to operate it (or pay for a managed service).
- SQS is right when you need a simple managed queue with at-least-once delivery to one consumer pool, and you're already in AWS.
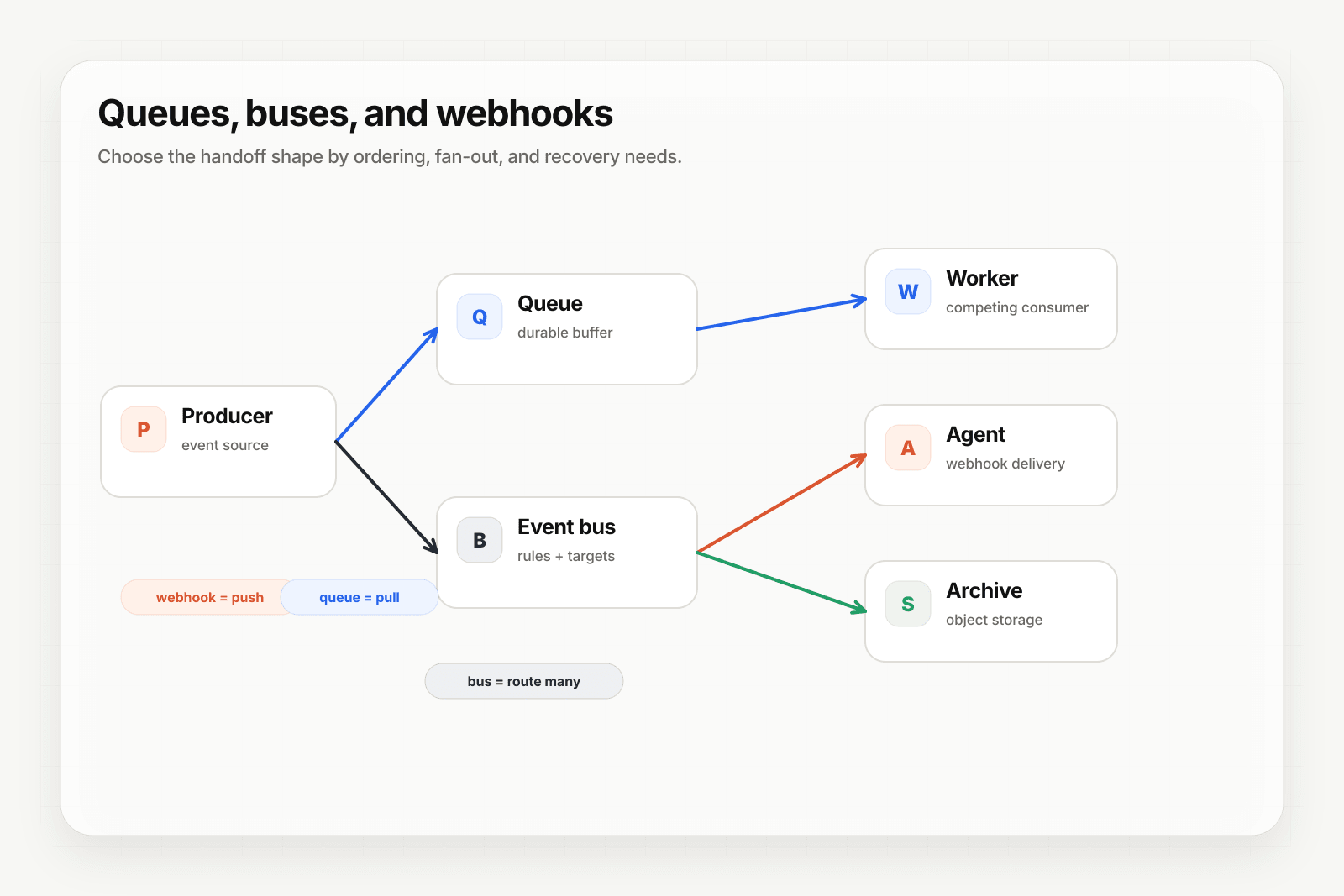
- A webhook relay in front of either is right when the events come from outside your trust boundary — webhooks, emails, forms — because it gives you HTTP-aware ingest and a customer-facing delivery history that neither Kafka nor SQS provides.
Most teams default to "we'll use Kafka because it's the powerful one." Most teams should default to SQS plus a relay and only reach for Kafka when a specific feature actually matters.
How they differ at the model level
| Kafka | SQS | |
|---|---|---|
| Storage model | Append-only log per topic, partitioned | Distributed queue per queue |
| Consumer model | Consumer groups, each tracks its own offset | Consumers compete for messages from one pool |
| Replay | Yes — read from any offset | No — once deleted, gone (within 14-day retention) |
| Ordering | Strict within a partition | Best-effort (Standard) or strict per group ID (FIFO) |
| Throughput | Very high (millions/sec at scale) | High (Standard); limited (FIFO) |
| Operations | You operate it (or pay for managed) | Fully managed |
| Cost | Self-hosted is cheap at scale; managed is significant | Pay-per-request, scales with usage |
| Cross-org / external | No (internal only) | No (internal only) |
The most important practical difference: Kafka has consumer groups; SQS doesn't. A Kafka consumer group lets multiple consumers read the same data independently — analytics reads from offset A, billing reads from offset B, both at their own pace. SQS doesn't have this; you'd run multiple queues with SNS in front (or use EventBridge).
When Kafka wins
Kafka is the right tool when:
- You need replay from an arbitrary offset. Your analytics team wants to reprocess last week's events with new logic. Kafka stores them; SQS doesn't.
- You have multiple independent consumer groups reading the same stream. Three teams (analytics, billing, ML training) each consume the same event log without coordinating.
- You need strict ordering at scale within partition keys. Kafka's per-partition ordering at high throughput is unique among managed-or-self-hosted options.
- You're handling high throughput (millions of events per second). At that scale, SQS's per-queue limits and per-message cost add up.
- You want schema enforcement via a schema registry (Confluent or similar).
The catch: Kafka is operationally heavy. Self-hosted Kafka requires brokers, ZooKeeper or KRaft, partition rebalancing, and ongoing tuning. Managed services (MSK, Confluent Cloud, Redpanda Cloud) reduce the operational burden but cost real money.
When SQS wins
SQS is the right tool when:
- You're already in AWS and don't want to operate a broker.
- You have one consumer pool doing the work; competing consumers pull from the queue.
- The throughput is moderate (thousands to tens of thousands of messages per second).
- You don't need to replay events outside SQS's 14-day retention.
- You don't need multiple independent consumers of the same data (or you're willing to use SNS or EventBridge for that).
For most "we have webhooks coming in and need to process them async with retries" cases, SQS is the right default. The infrastructure burden is near zero.
When the answer is neither — it's a relay in front
This is where most teams over-engineer. The question "Kafka or SQS for webhook fan-out?" assumes the webhook ingest layer is solved. It usually isn't.
The pattern that actually works for most teams:
Provider webhook → webhook relay → SQS (or Kafka, or your handler directly)
The relay handles:
- HTTP ingest with supported provider verification after ingest auth
- Retries with backoff to the destination
- A retained payload log (independent of SQS retention or Kafka topic config)
- Replay from the dashboard while the payload is retained
- Delivery history queryable by event or customer
- DLQ for terminal failures
Then SQS (or Kafka) handles internal fan-out if you actually need it.
For a single agent consumer, you don't need SQS or Kafka at all — the relay's retry-and-delivery primitives are sufficient. For two consumers, an SNS topic with two SQS subscriptions is simpler than Kafka. For five-plus independent consumer groups with replay, Kafka starts to make sense.
Hooksbase is one such relay — it has SQS, EventBridge, GCP Pub/Sub, and S3 as typed destinations, so the relay can dispatch directly to your queue or topic without an intermediate Lambda.
Failure modes worth knowing
Each option has its quirks.
Kafka failure modes:
- Partition rebalancing during consumer scale events can pause processing
- Disk pressure on brokers when retention is long and topics are large
- ZooKeeper or controller failures (less common with KRaft)
- Schema mismatch when producers and consumers evolve independently
SQS failure modes:
- Hitting the 256 KB message limit (use S3 + reference)
- Messages stuck in-flight when consumer crashes (visibility timeout helps)
- Hitting the 120K in-flight limit on Standard queues
- Forgetting to set up a DLQ (failed messages just keep redelivering forever)
Relay-in-front failure modes:
- Misconfiguring the destination so events succeed at the relay but fail at the queue
- Idempotency keys that don't match between the relay's
webhook-idand the downstream's deduplication
All of these are operable. None are dealbreakers. They're worth knowing before you commit.
Where to go next
- What is SQS? for the SQS primer
- What is EventBridge? for AWS's pub/sub layer
- What is a message queue? for the broader concept
- Webhook DLQs: design and recovery patterns for the failure-recovery side